Initial Configuration¶
Leverage Initial Access Intelligence detection artifacts to detect & respond to remote code execution (RCE) vulnerabilities. See our Intial Access Intelligence Weekly Release Notes for more information.
import os
import vulncheck_sdk
import matplotlib.pyplot as plt
import pandas as pd
import plotly.express as px
import calplot
import sys
from dotenv import load_dotenv
load_dotenv()
DEFAULT_HOST = "https://api.vulncheck.com"
DEFAULT_API = DEFAULT_HOST + "/v3"
TOKEN = os.environ["VULNCHECK_API_TOKEN"]
# Configure the VulnCheck API client
configuration = vulncheck_sdk.Configuration(host=DEFAULT_API)
configuration.api_key["Bearer"] = TOKENPull Data¶
import sys
sys.path.insert(0, "..")
from utils import load_index
# ========= Helpers =========
def _as_bool(x):
if isinstance(x, bool):
return x
if x is None or (isinstance(x, float) and pd.isna(x)):
return False
return str(x).strip().lower() in {"true", "1", "yes", "y", "t"}
def _coalesce_attr(obj, *names, default=None):
for n in names:
if hasattr(obj, n):
return getattr(obj, n)
return default
def _join_list(val):
if isinstance(val, (list, tuple, set)):
return ", ".join(map(str, val)) if val else "N/A"
if val in (None, ""):
return "N/A"
return str(val)
def _slice_date10(val):
if not val:
return "N/A"
return str(val)[:10]
# ========= 1) Initial Access -> artifact rows =========
rows = []
for entry in load_index("initial-access"):
cve = _coalesce_attr(entry, "cve")
in_kev = _coalesce_attr(entry, "in_kev", "inKEV", default=False)
in_vckev = _coalesce_attr(entry, "in_vckev", "inVCKEV", default=False)
artifacts = getattr(entry, "artifacts", []) or []
if artifacts:
for a in artifacts:
rows.append({
"CVE": cve,
"inKEV": _as_bool(in_kev),
"inVCKEV": _as_bool(in_vckev),
"Artifact Vendor": _join_list(_coalesce_attr(a, "vendor")),
"Artifact Product": _join_list(_coalesce_attr(a, "product", default=[])),
"Artifact Name": _coalesce_attr(a, "artifact_name", "artifactName", default="N/A"),
"Exploit": _as_bool(_coalesce_attr(a, "exploit", default=False)),
"PCAP": _as_bool(_coalesce_attr(a, "pcap", default=False)),
"Suricata Rule": _as_bool(_coalesce_attr(a, "suricata_rule", "suricataRule", default=False)),
"Snort Rule": _as_bool(_coalesce_attr(a, "snort_rule", "snortRule", default=False)),
"YARA": _as_bool(_coalesce_attr(a, "yara", default=False)),
"Nmap Script": _as_bool(_coalesce_attr(a, "nmap_script", "nmapScript", default=False)),
"ZeroDay": _as_bool(_coalesce_attr(a, "zeroday", "zero_day", default=False)),
"versionScanner": _as_bool(_coalesce_attr(a, "version_scanner", "versionScanner", default=False)),
"targetDocker": _as_bool(_coalesce_attr(a, "target_docker", "targetDocker", default=False)),
"sigmaRule": _as_bool(_coalesce_attr(a, "sigma_rule", "sigmaRule", default=False)),
"Artifact Date Added": _slice_date10(_coalesce_attr(a, "date_added", "dateAdded")),
})
else:
rows.append({
"CVE": cve,
"inKEV": _as_bool(in_kev),
"inVCKEV": _as_bool(in_vckev),
"Artifact Vendor": "N/A", "Artifact Product": "N/A", "Artifact Name": "N/A",
"Exploit": False, "PCAP": False, "Suricata Rule": False, "Snort Rule": False,
"YARA": False, "Nmap Script": False, "ZeroDay": False,
"versionScanner": False, "targetDocker": False, "sigmaRule": False,
"Artifact Date Added": "N/A",
})
df_artifact_level = pd.DataFrame(rows)
# ========= 2) Aggregate to CVE level =========
df_cve_level = df_artifact_level.groupby(
["CVE", "inKEV", "inVCKEV"], as_index=False
).agg({
"Artifact Vendor": lambda x: sorted(set(x)),
"Artifact Product": lambda x: sorted(set(x)),
"Artifact Name": lambda x: sorted(set(x)),
"Exploit": "max", "PCAP": "max", "Suricata Rule": "max", "Snort Rule": "max",
"YARA": "max", "Nmap Script": "max", "ZeroDay": "max",
"versionScanner": "max", "targetDocker": "max", "sigmaRule": "max",
"Artifact Date Added": lambda x: sorted(set(x)),
})
for col in ["Artifact Vendor", "Artifact Product", "Artifact Name", "Artifact Date Added"]:
df_cve_level[col] = df_cve_level[col].apply(lambda v: ", ".join(v) if isinstance(v, list) else v)
# ========= 3) VulnCheck KEV -> KEV dates per CVE =========
kev_rows = []
for entry in load_index("vulncheck-kev"):
cve = entry.cve[0] if isinstance(entry.cve, (list, tuple)) and entry.cve else entry.cve
vc_date = _slice_date10(_coalesce_attr(entry, "date_added", "dateAdded"))
cisa_raw = _coalesce_attr(entry, "cisa_date_added", "cisaDateAdded")
cisa_date = _slice_date10(cisa_raw) if cisa_raw else "none"
kev_rows.append({"CVE": cve, "vcKEV Date Added": vc_date, "CISA Date Added": cisa_date})
df_kev = pd.DataFrame(kev_rows)
def _min_str_date(series, none_token):
vals = [v for v in series if v and v not in {"N/A", none_token}]
return min(vals) if vals else none_token
df_kev = df_kev.groupby("CVE", as_index=False).agg({
"vcKEV Date Added": lambda s: _min_str_date(s, "N/A"),
"CISA Date Added": lambda s: _min_str_date(s, "none"),
})
# ========= 4) Merge -> df_final =========
df_final = df_cve_level.merge(df_kev, on="CVE", how="left")
insert_at = df_final.columns.get_loc("Artifact Date Added") if "Artifact Date Added" in df_final.columns else len(df_final.columns)
df_final.insert(insert_at, "Date Added", df_final["vcKEV Date Added"])
desired_order = [
"CVE", "inKEV", "inVCKEV",
"Date Added", "CISA Date Added", "Artifact Date Added",
"Artifact Vendor", "Artifact Product", "Artifact Name",
"Exploit", "PCAP", "Suricata Rule", "Snort Rule", "YARA",
"Nmap Script", "ZeroDay", "versionScanner", "targetDocker", "sigmaRule",
"vcKEV Date Added",
]
df_final = df_final[[c for c in desired_order if c in df_final.columns]]
print("artifact-level rows:", len(df_artifact_level))
print("cve-level rows :", len(df_cve_level))
print("kev rows (unique) :", len(df_kev))
print("final rows :", len(df_final))artifact-level rows: 902
cve-level rows : 889
kev rows (unique) : 4978
final rows : 889
# Start with your consolidated dataframe
df = df_final.copy()
# ===== Ensure expected columns exist =====
base_expected = {"CVE", "Exploit", "inKEV", "inVCKEV"}
extra_expected = {
"PCAP", "Suricata Rule", "Snort Rule", "YARA",
"versionScanner", "targetDocker", "sigmaRule"
}
expected_cols = base_expected | extra_expected
missing = expected_cols - set(df.columns)
missing_base = missing & base_expected
if missing_base:
raise KeyError(f"Missing required columns in dataframe: {sorted(missing_base)}")
# Create missing "extra" columns (assume False)
for col in (missing & extra_expected):
df[col] = False
# ===== Normalize boolean-like columns =====
def to_bool_safe(val):
"""Coerce various truthy/falsey representations to a clean boolean."""
if pd.isna(val):
return False
if isinstance(val, bool):
return val
s = str(val).strip().lower()
return s in ("true", "1", "yes", "y", "t")
boolish_cols = [
"Exploit", "inKEV", "inVCKEV",
"PCAP", "Suricata Rule", "Snort Rule", "YARA",
"versionScanner", "targetDocker", "sigmaRule"
]
for col in boolish_cols:
df.loc[:, col] = df[col].apply(to_bool_safe)
# ==========
# METRICS (ALL IAI)
# ==========
scope_label = "CVE Coverage"
total_cves = df["CVE"].nunique()
total_exploits = int(df["Exploit"].sum())
total_inKEV = int(df["inKEV"].sum())
total_inVCKEV = int(df["inVCKEV"].sum())
total_pcap = int(df["PCAP"].sum())
total_suricata = int(df["Suricata Rule"].sum())
total_snort = int(df["Snort Rule"].sum())
total_yara = int(df["YARA"].sum())
total_version_scanner = int(df["versionScanner"].sum())
total_target_docker = int(df["targetDocker"].sum())
total_sigma_rules = int(df["sigmaRule"].sum())
# ==========
# TABLE
# ==========
rows = [
("CVEs in IAI", total_cves),
("Exploits in IAI", total_exploits),
("IAI in CISA KEV", total_inKEV),
("IAI in VulnCheck KEV", total_inVCKEV),
("CVEs with PCAP", total_pcap),
("CVEs with Suricata Rule", total_suricata),
("CVEs with Snort Rule", total_snort),
("CVEs with YARA", total_yara),
("CVEs with Version Scanner", total_version_scanner),
("CVEs with Target Docker", total_target_docker),
("CVEs with Sigma rules", total_sigma_rules)
]
iai_stats_df = pd.DataFrame(rows, columns=["Initial Access Exploits & Detection Artifacts", scope_label])
iai_stats_df[scope_label] = iai_stats_df[scope_label].astype(int)
# Optional: style for notebook display
styled_iai_stats_df = (
iai_stats_df.style
.set_properties(**{"text-align": "center"})
.set_table_styles([{"selector": "th", "props": [("text-align", "center")]}])
.set_table_attributes('style="width:100%; border-collapse: collapse;"')
.hide(axis="index")
)
styled_iai_stats_df
Loading...
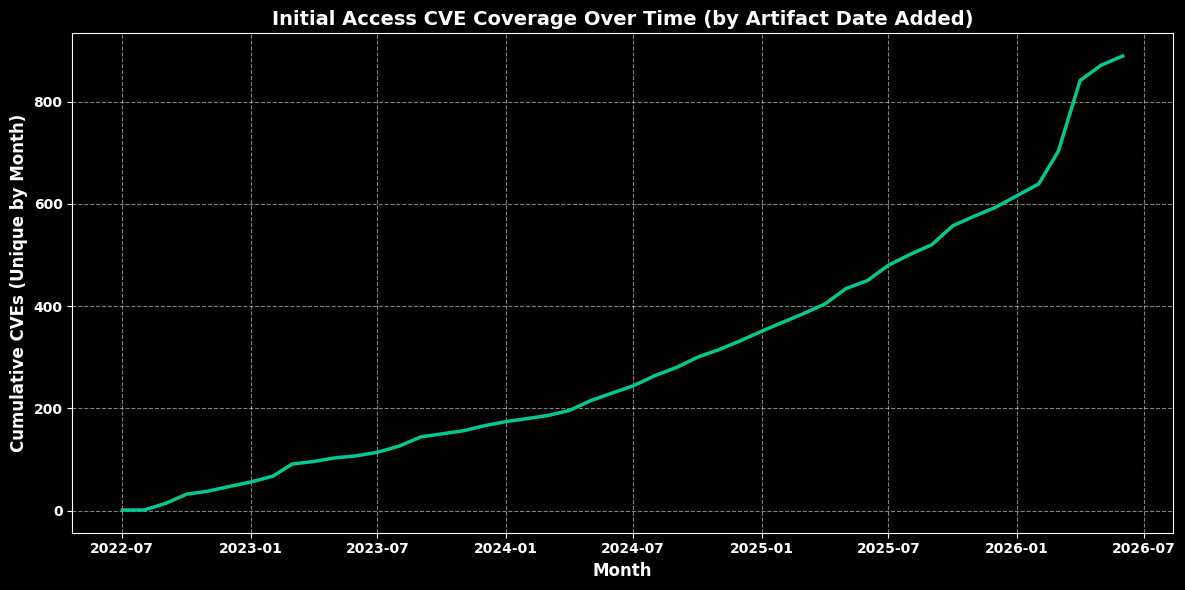
Initial Access Coverage Over Time¶
# Parse "Artifact Date Added"
def parse_earliest_date(val):
if pd.isna(val):
return pd.NaT
if isinstance(val, (list, tuple, set)):
parts = list(val)
else:
parts = [x.strip() for x in str(val).split(",")]
parsed = [pd.to_datetime(x, errors="coerce") for x in parts]
parsed = [d for d in parsed if not pd.isna(d)]
return min(parsed) if parsed else pd.NaT
df_final["Artifact Date Parsed"] = df_final["Artifact Date Added"].apply(parse_earliest_date)
df_final = df_final.dropna(subset=["Artifact Date Parsed"])
# --- Count unique CVEs per month ---
monthly_counts = (
df_final
.groupby(df_final["Artifact Date Parsed"].dt.to_period("M"))["CVE"]
.nunique()
.rename("count")
.to_timestamp()
)
# Fill missing months for smooth cumulative line
if not monthly_counts.empty:
full_month_index = pd.date_range(
start=monthly_counts.index.min(),
end=monthly_counts.index.max(),
freq="MS"
)
monthly_counts = monthly_counts.reindex(full_month_index, fill_value=0)
cumulative_counts = monthly_counts.cumsum()
# --- Plot cumulative chart in dark mode ---
plt.style.use("dark_background")
plt.figure(figsize=(12, 6))
plt.plot(cumulative_counts.index, cumulative_counts.values, linewidth=2.5, color="#00c893")
plt.title("Initial Access CVE Coverage Over Time (by Artifact Date Added)",
fontsize=14, color="white", fontweight="bold")
plt.xlabel("Month", fontsize=12, color="white", fontweight="bold")
plt.ylabel("Cumulative CVEs (Unique by Month)", fontsize=12, color="white", fontweight="bold")
plt.xticks(fontsize=10, color="white", fontweight="bold")
plt.yticks(fontsize=10, color="white", fontweight="bold")
plt.grid(True, linestyle="--", alpha=0.5)
plt.tight_layout()
plt.show()
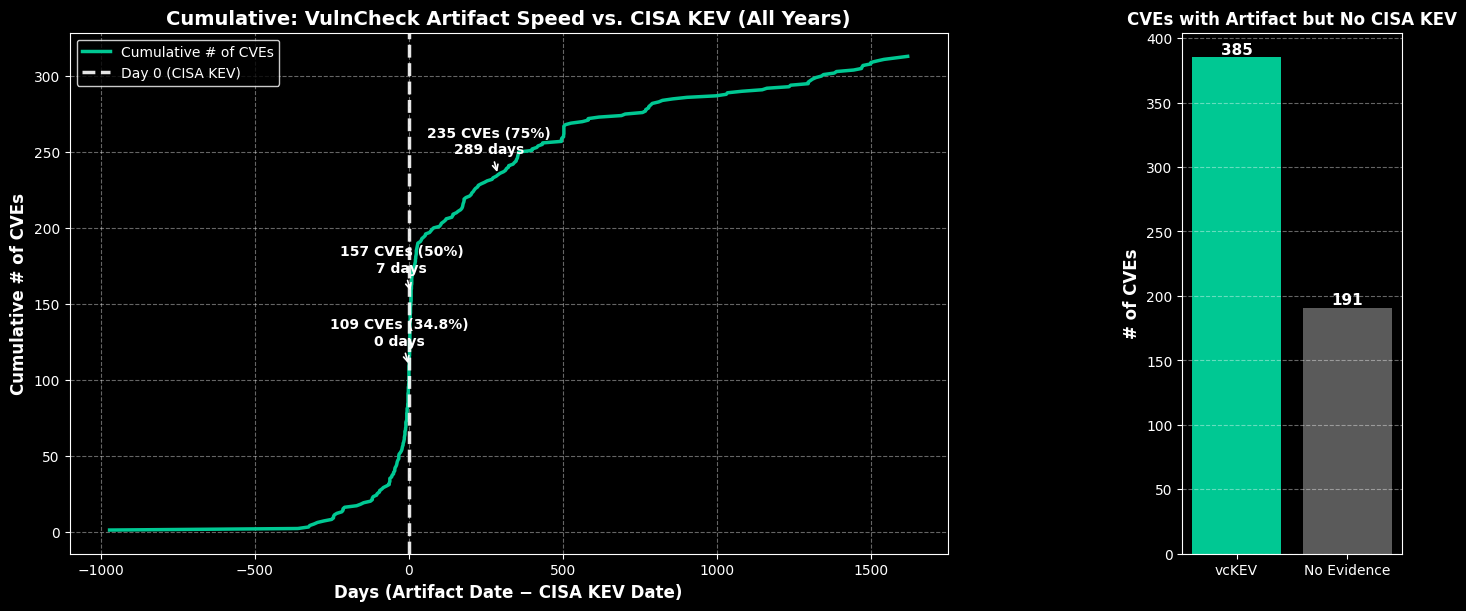
VulnCheck Exploit & Detection Artifact Availability vs. CISA KEV¶
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = df_final.copy()
# ---- Helpers ----
def parse_dates_list(val):
if pd.isna(val):
return []
if isinstance(val, (list, tuple, set)):
parts = list(val)
else:
parts = [x.strip() for x in str(val).split(",")]
parsed = [pd.to_datetime(x, errors="coerce") for x in parts]
return [d for d in parsed if not pd.isna(d)]
def parse_single_date(val):
if pd.isna(val):
return pd.NaT
s = str(val).strip()
if s.lower() in ("none", "n/a", "na", ""):
return pd.NaT
return pd.to_datetime(s, errors="coerce")
def to_bool_safe(val):
if pd.isna(val):
return False
if isinstance(val, bool):
return val
return str(val).strip().lower() in ("true", "1", "yes", "y", "t")
# ---- Derive in a working copy (original untouched) ----
working = df.copy()
working["Artifact Dates (list)"] = working["Artifact Date Added"].apply(parse_dates_list)
working["Earliest Artifact Date"] = working["Artifact Dates (list)"].apply(lambda lst: min(lst) if lst else pd.NaT)
working["CISA Date (parsed)"] = working["CISA Date Added"].apply(parse_single_date)
if "inVCKEV" in working.columns:
working["inVCKEV"] = working["inVCKEV"].apply(to_bool_safe)
# =========================
# LEFT: cumulative counts for CVEs WITH both dates
# =========================
cve_dates_all = (
working.groupby("CVE", as_index=False)[["Earliest Artifact Date", "CISA Date (parsed)"]]
.min()
)
# Keep those with BOTH dates
both_dates = cve_dates_all.dropna(subset=["Earliest Artifact Date", "CISA Date (parsed)"]).copy()
# Inverse delta: Artifact - CISA (positive => VulnCheck earlier/faster)
delta_col = "Delta Days (Artifact - CISA)"
both_dates[delta_col] = (
both_dates["Earliest Artifact Date"] - both_dates["CISA Date (parsed)"]
).dt.days
# Valid numeric deltas
delta_df = both_dates[pd.to_numeric(both_dates[delta_col], errors="coerce").notna()].copy()
values = np.sort(delta_df[delta_col].values) # sorted day deltas
if len(values) == 0:
raise ValueError("No valid deltas to plot. Ensure there are artifact + CISA dates.")
cum_counts = np.arange(1, len(values) + 1) # 1..N
N = len(values)
def x_at_count(target_count: int) -> int:
idx = np.searchsorted(cum_counts, target_count, side="left")
idx = min(idx, N - 1)
return int(values[idx])
def count_at_x(x_val: int) -> int:
return int((values <= x_val).sum())
# Markers (counts)
y_zero = count_at_x(0)
pct_zero = y_zero / N * 100.0
x_zero = 0
y_50 = int(np.ceil(0.50 * N))
x_50 = x_at_count(y_50)
y_75 = int(np.ceil(0.75 * N))
x_75 = x_at_count(y_75)
# =========================
# RIGHT: bar for CVEs MISSING CISA date (by inVCKEV)
# =========================
with_artifact = working.dropna(subset=["Earliest Artifact Date"])
missing_cisa = with_artifact[with_artifact["CISA Date (parsed)"].isna()].copy()
if "inVCKEV" in missing_cisa.columns:
invc = (missing_cisa.groupby("CVE")["inVCKEV"].max().reset_index())
else:
invc = missing_cisa[["CVE"]].drop_duplicates()
invc["inVCKEV"] = False
bar_counts = invc["inVCKEV"].value_counts().reindex([True, False], fill_value=0)
bar_labels = ["vcKEV", "No Evidence"]
bar_values = [int(bar_counts.get(True, 0)), int(bar_counts.get(False, 0))]
# =========================
# Plot (two-panel figure) — constrained layout
# =========================
plt.style.use("dark_background")
fig, (ax1, ax2) = plt.subplots(
1, 2,
figsize=(14, 6),
gridspec_kw={"width_ratios": [4, 1], "wspace": 0.25},
constrained_layout=True
)
# LEFT panel: cumulative line (counts)
ax1.plot(values, cum_counts, color="#00c893", linewidth=2.5, label="Cumulative # of CVEs")
ax1.axvline(0, linestyle="--", linewidth=2.5, color="white", alpha=0.9, label="Day 0 (CISA KEV)")
max_y = N
y_offset = max(5, int(0.04 * max_y))
x_offset = 30
annotations = [
(x_zero, y_zero, f"{y_zero} CVEs ({pct_zero:.1f}%)\n{int(x_zero)} days"),
(x_50, y_50, f"{y_50} CVEs (50%)\n{int(x_50)} days"),
(x_75, y_75, f"{y_75} CVEs (75%)\n{int(x_75)} days"),
]
for x, y, label in annotations:
ax1.annotate(
label,
xy=(x, y),
xytext=(x - x_offset, min(y + y_offset, max_y)),
textcoords="data",
arrowprops=dict(arrowstyle="->", color="white", lw=1.2),
ha="center", va="bottom",
fontsize=10, color="white", fontweight="bold"
)
ax1.set_title("Cumulative: VulnCheck Artifact Speed vs. CISA KEV (All Years)",
fontsize=14, color="white", fontweight="bold")
ax1.set_xlabel("Days (Artifact Date − CISA KEV Date)", fontsize=12, color="white", fontweight="bold")
ax1.set_ylabel("Cumulative # of CVEs", fontsize=12, color="white", fontweight="bold")
ax1.tick_params(colors="white", labelsize=10)
ax1.grid(True, linestyle="--", alpha=0.4)
ax1.legend(facecolor="black", edgecolor="white")
# RIGHT panel: bar for missing CISA KEV coverage
bar_colors = ["#00c893", "#5a5a5a"] # vcKEV => green, No Evidence => gray
bars = ax2.bar(bar_labels, bar_values, color=bar_colors)
for rect in bars:
height = rect.get_height()
ax2.text(rect.get_x() + rect.get_width()/2, height,
f"{int(height)}", ha="center", va="bottom",
fontsize=11, color="white", fontweight="bold")
ax2.set_title("CVEs with Artifact but No CISA KEV", fontsize=12, color="white", fontweight="bold")
ax2.set_ylabel("# of CVEs", fontsize=12, color="white", fontweight="bold")
ax2.tick_params(colors="white", labelsize=10)
ax2.grid(axis="y", linestyle="--", alpha=0.4)
plt.show()
IAI Exploit & Detection Artifact Vendor Coverage¶
import pandas as pd
import plotly.express as px
# --- Use df_cve_level from previous script ---
# Expand rows in case a CVE has multiple vendors
df_vendors = df_cve_level.explode("Artifact Vendor")
# Count unique CVEs per vendor
vendor_counts = df_vendors.groupby("Artifact Vendor")["CVE"].nunique().reset_index(name="Counts")
# Truncate vendor names for readability (optional)
vendor_counts["Artifact Vendor"] = vendor_counts["Artifact Vendor"].str.slice(0, 20)
# Create a treemap with Plotly Express
fig = px.treemap(
vendor_counts,
path=["Artifact Vendor"],
values="Counts",
color="Counts",
color_continuous_scale="Viridis"
)
# Customize dark mode layout
fig.update_layout(
title="Artifact Vendors by Number of CVEs",
title_font=dict(size=20, color="white"),
title_x=0.5,
paper_bgcolor="black",
plot_bgcolor="black",
margin=dict(t=50, l=25, r=25, b=25),
width=1200,
height=800
)
# Remove color bar
fig.update_coloraxes(showscale=False)
# Style labels
fig.update_traces(
texttemplate="%{label}<br>%{value}",
textfont_size=16,
textfont_color="white"
)
# Show the interactive treemap
fig.show()
Loading...